Topic
AI Safety & Alignment
Alignment research, red teaming, evals, and safer deployment practices
Featured


DeepMind CEO backs independent standards body for frontier AI

Savi launches AI scam detector app after $7M seed round
All Stories

OpenAI Proposes State-Led Path to National AI Governance
OpenAI has outlined a 'reverse federalism' approach to AI governance in which state-level laws work together to…

ScienceSoft builds HIPAA-compliant AI voice scheduler on AWS
ScienceSoft has built a HIPAA-compliant AI voice scheduler using Amazon Nova Sonic and Amazon Bedrock Guardrails on AWS…

The AI Evaluation Gap: Agents Outpacing Assurance
Half of enterprises have deployed AI agents that passed internal evaluations but still failed in production, yet 66%…

Multi-Model AI Systems Fail More Often Than Enterprises Realize
A study of 67 frontier models from 21 providers reveals that enterprises using multiple AI models significantly…

Bernanke Joins Anthropic's Governance Trust
Anthropic's Long-Term Benefit Trust appointed former Federal Reserve Chair Ben Bernanke as its fourth member on…

OpenAI Sets Principles for Government AI Partnerships
OpenAI has published principles for its approach to government and national security partnerships, outlining frameworks…

Anthropic finds consciousness-like structure in Claude
Anthropic published research showing that Claude language models have spontaneously developed an internal structure…

Patronus AI raises $50M to stress-test AI agents
Patronus AI, a startup founded by former Meta AI researchers, has raised $50 million to build digital worlds designed…

OpenAI backs shared standards for advanced AI safety
OpenAI is supporting the development of shared standards for advanced AI systems, working through the Appia Foundation…

DeepMind Publishes AI Control Roadmap for Agent Security
Google DeepMind has published an AI Control Roadmap focused on securing internal systems that deploy AI agents,…

Google's 'Faithful Uncertainty' Lets LLMs Hedge Instead of Hallucinate
Google researchers propose 'faithful uncertainty,' a technique that allows large language models to express qualified…

DeepMind commits $10M to multi-agent AI safety research
Google DeepMind and partners have announced a $10M funding call dedicated to multi-agent AI safety research. The…

Anthropic Pushes FAA-Style AI Regulation, Enterprises Face Supply Chain Risk
Anthropic CEO Dario Amodei published a policy essay calling for FAA-style government regulation of powerful AI models,…

OpenAI backs EU transparency code for AI-generated content
OpenAI has announced support for the EU Code of Practice on AI content transparency, committing to advance provenance…

Waymo models human crash avoidance to improve autonomous vehicle safety
Waymo published research in Nature Communications describing a computer-based cognitive model that explains how human…

Anthropic Warns on Recursive Self-Improvement Even as Industry Races Ahead
Anthropic announced that Claude now writes 80% of its code, highlighting progress toward recursive self-improvement,…

Illinois Passes AI Safety Audit and Whistleblower Bill
The Illinois House of Representatives passed legislation requiring major AI companies to submit model safety plans for…

AI-Generated Story Slips Into Prestigious Literary Prize
An AI-generated short story appears to have won selection in Granta magazine's Commonwealth Short Story Prize, a…

AI Therapy Startup Claims Major Safety Advantage Over Consumer Bots
The Path, a startup founded by veterans from Tony Robbins' organization and Calm, claims its AI therapy model scored 95…
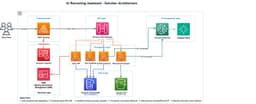
AWS Demonstrates AI Recruitment Assistant Using Bedrock
AWS published a reference architecture for building an AI-powered recruitment assistant using Amazon Bedrock that…

NanoCo AI Raises $12M to Build Secure Enterprise AI Assistants
NanoCo AI, founded by former Wix engineer Gavriel Cohen and his brother Lazer Cohen, has raised a $12 million…

OpenAI Launches Content Provenance Tools to Verify AI-Generated Media
OpenAI has introduced a suite of tools focused on content provenance, including Content Credentials and SynthID, along…
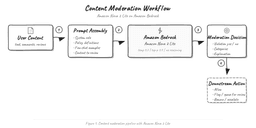
Amazon Nova 2 Lite for Content Moderation via Prompting
AWS published a guide on using Amazon Nova 2 Lite for content moderation via prompting, demonstrating how to apply the…

ArXiv to ban authors for a year over AI-generated papers
ArXiv, the preprint repository used by researchers across physics, mathematics, computer science, and other fields, is…