Amazon Nova 2 Lite for Content Moderation via Prompting
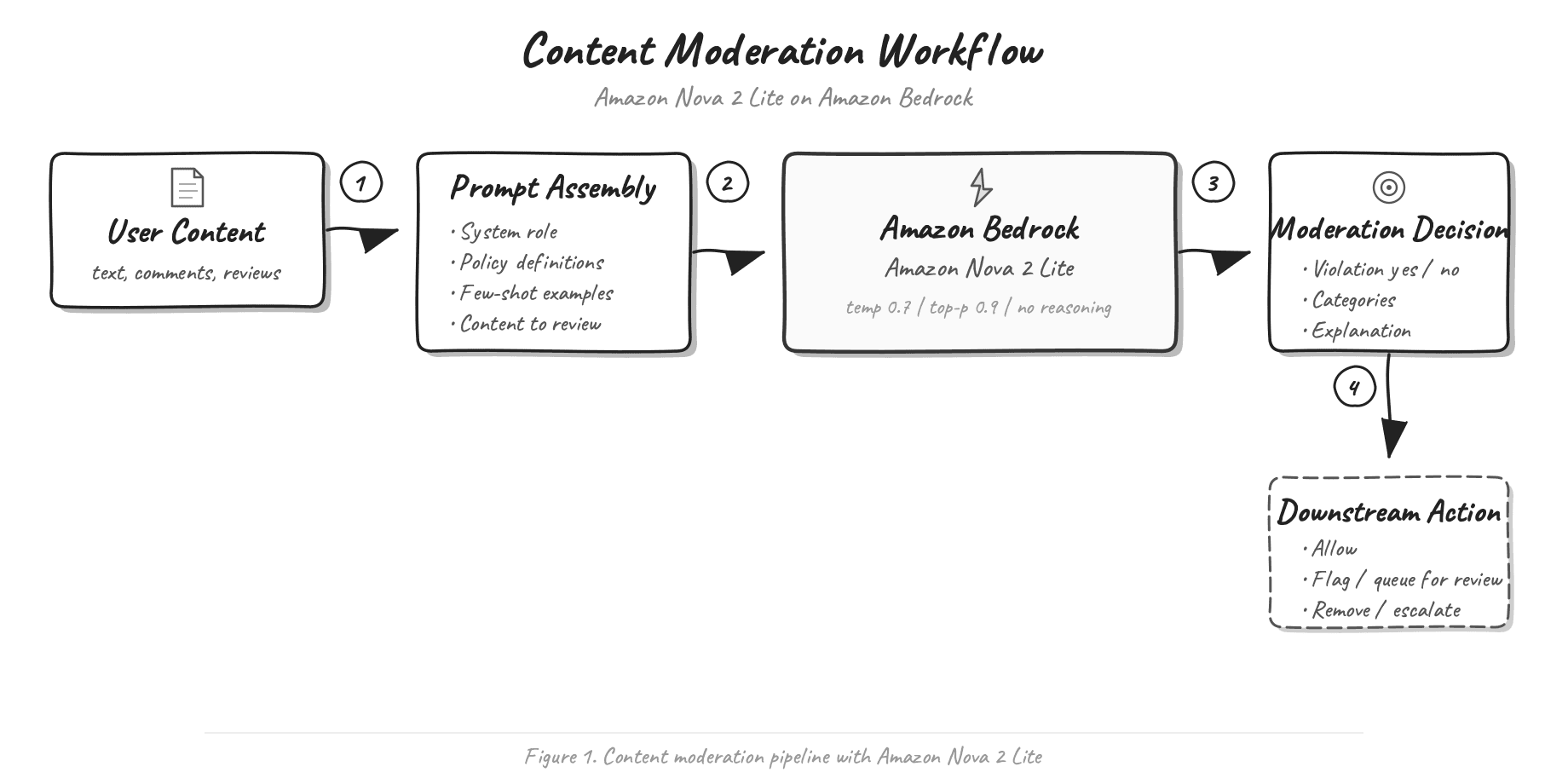
AWS published a guide on using Amazon Nova 2 Lite for content moderation via prompting, demonstrating how to apply the MLCommons AILuminate Assessment Standard's 12-category hazard taxonomy without requiring model fine-tuning. The approach allows organizations to update moderation policies by editing prompts rather than retraining models, and includes benchmarks comparing Nova 2 Lite against other foundation models on public datasets. The technique works with both the AILuminate taxonomy and custom moderation policies, making it adaptable to different organizational needs.
TL;DR
- Amazon Nova 2 Lite can be prompted for content moderation using structured and free-form approaches without fine-tuning
- The MLCommons AILuminate Assessment Standard provides a 12-category hazard taxonomy organized into Physical, Non-Physical, and Contextual harm groups
- Prompt-based moderation allows policy updates without model retraining, reducing operational friction for policy changes
- AWS benchmarked Nova 2 Lite against other foundation models on three public datasets for content moderation tasks
Why It Matters
Content moderation at scale requires balancing precision against recall, missing harmful content versus over-flagging legitimate posts. A standardized taxonomy like AILuminate provides a common framework for evaluating moderation performance across models and organizations. Prompt-based approaches lower the barrier to deployment and policy iteration compared to fine-tuning workflows.
Business Impact
Organizations managing user-generated content can deploy moderation systems faster without labeled training data or model customization infrastructure. The ability to update policies through prompt editing rather than retraining reduces time-to-deployment and operational costs, while benchmarking against foundation models helps teams select the right model for their specific accuracy and latency requirements.
Key Implications
- Prompting offers a faster path to production for content moderation than fine-tuning, lowering barriers for smaller teams and organizations with limited ML infrastructure
- Standardized taxonomies like AILuminate enable cross-organizational comparison of moderation performance and reduce the need for custom policy definitions from scratch
- The approach is policy-agnostic, meaning organizations can swap custom category definitions into the same prompt structure, supporting diverse moderation requirements across industries
What to Watch
Monitor how organizations adopt standardized taxonomies versus custom policies in production, and whether prompt-based moderation achieves comparable accuracy to fine-tuned models at scale. Watch for emerging benchmarks on moderation performance across different foundation models and whether the approach handles edge cases and context-dependent violations effectively.
Subscribe to the newsletter
The latest stories and analysis, delivered to your inbox.
Free. No spam. Unsubscribe any time.



