Google's Omni Flash API brings conversational video editing to enterprises

Google has released Gemini Omni Flash through an API for enterprise customers and developers, enabling conversational video editing and generation. The model consolidates multiple AI tools into a single interface that accepts text, images, and video as inputs and produces finished clips with synced audio. The API rollout makes the technology accessible to marketing and learning-and-development teams that produce most organizational videos, addressing the cost and timeline barriers that have historically limited internal video production.
TL;DR
- Gemini Omni Flash API now available to enterprises and developers after consumer debut at Google I/O 2026
- Conversational editing allows iterative changes to video without regenerating from scratch, reducing production cycles
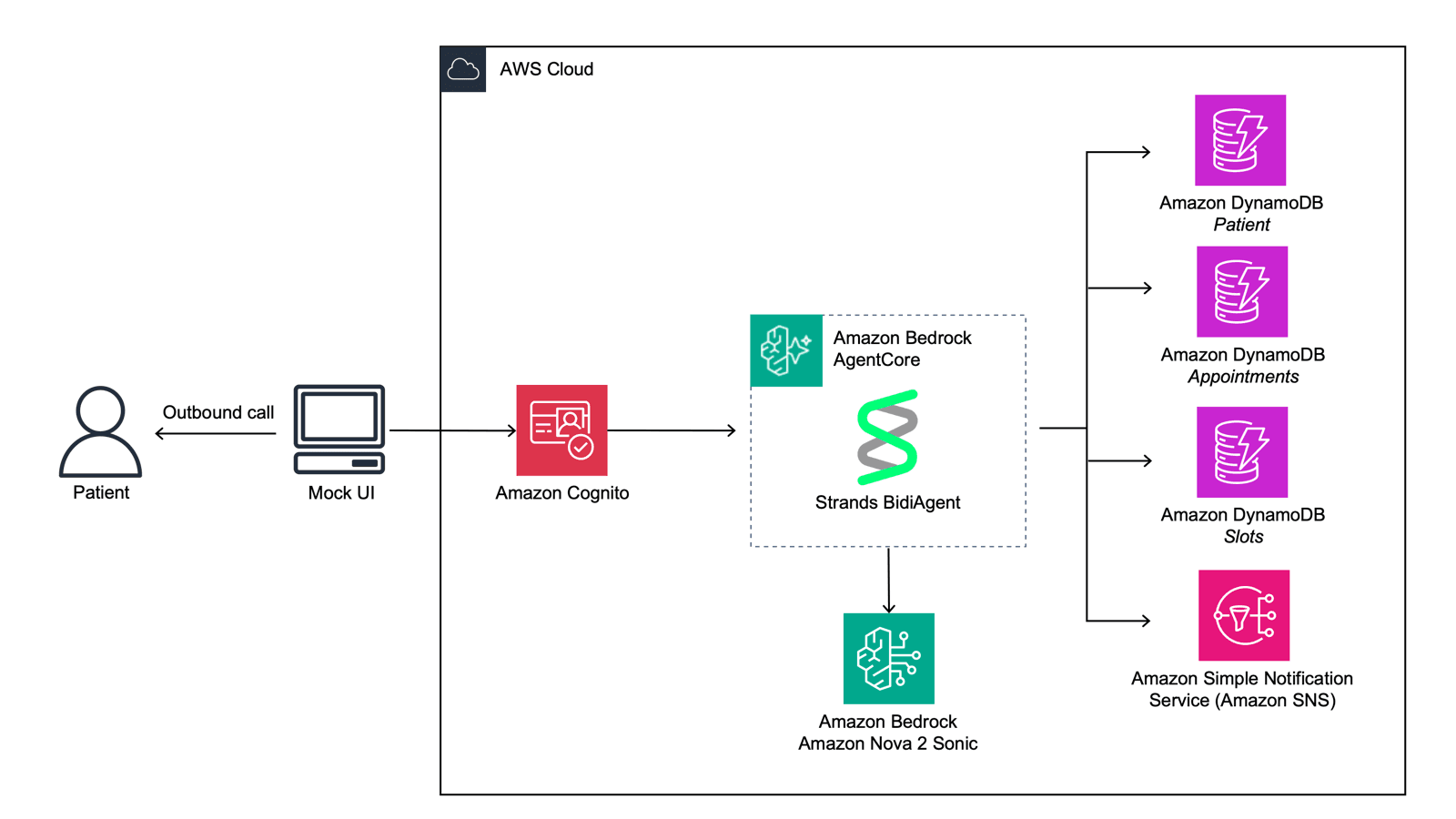
- Single unified model replaces multi-tool pipelines (LLM, text-to-image, image-to-video, lip-sync, voice generation), simplifying vendor management and data handling
- Supports multimodal inputs including reference images and existing video clips, with physics engine for realistic scene rendering and text/logo insertion capabilities
Why It Matters
Enterprise video production has been constrained by cost and timeline friction. Consolidating five separate AI tools into one conversational interface removes technical overhead that has prevented many organizations from adopting generative video. The ability to edit finished clips through conversation rather than regenerating from scratch fundamentally changes the economics of internal video creation.
Business Impact
Organizations can reduce video production timelines and vendor complexity while maintaining control over brand assets and data handling through a single platform. For teams that have avoided generative video due to tool integration overhead, the unified approach shifts the cost-benefit calculation in favor of adoption. Marketing and L&D departments can iterate on video content without external vendors or lengthy revision cycles.
Key Implications
- Consolidation of point tools into a single model reduces operational overhead and vendor management burden for enterprises
- Conversational editing capability enables rapid iteration on video content, reducing production timelines for training videos and product explainers
- Reference-driven control using product photos, logos, and location images allows brand-consistent output without relying solely on text prompts
- Text and logo insertion with scene-aware rendering creates opportunities for localized content and branded materials, though output quality still requires human review
What to Watch
Monitor adoption rates among marketing and L&D teams to assess whether the API actually reduces production timelines and costs as pitched. Track the accuracy of text insertion and logo placement in complex scenes, as the source notes imperfect tracking and frame consistency issues. Watch for enterprise customers reporting on data handling, compliance, and whether the unified model approach delivers the promised simplification over multi-tool pipelines.
Subscribe to the newsletter
The latest stories and analysis, delivered to your inbox.
Free. No spam. Unsubscribe any time.