SageMaker and vLLM Enable Real-Time Voice AI Without Custom Infrastructure
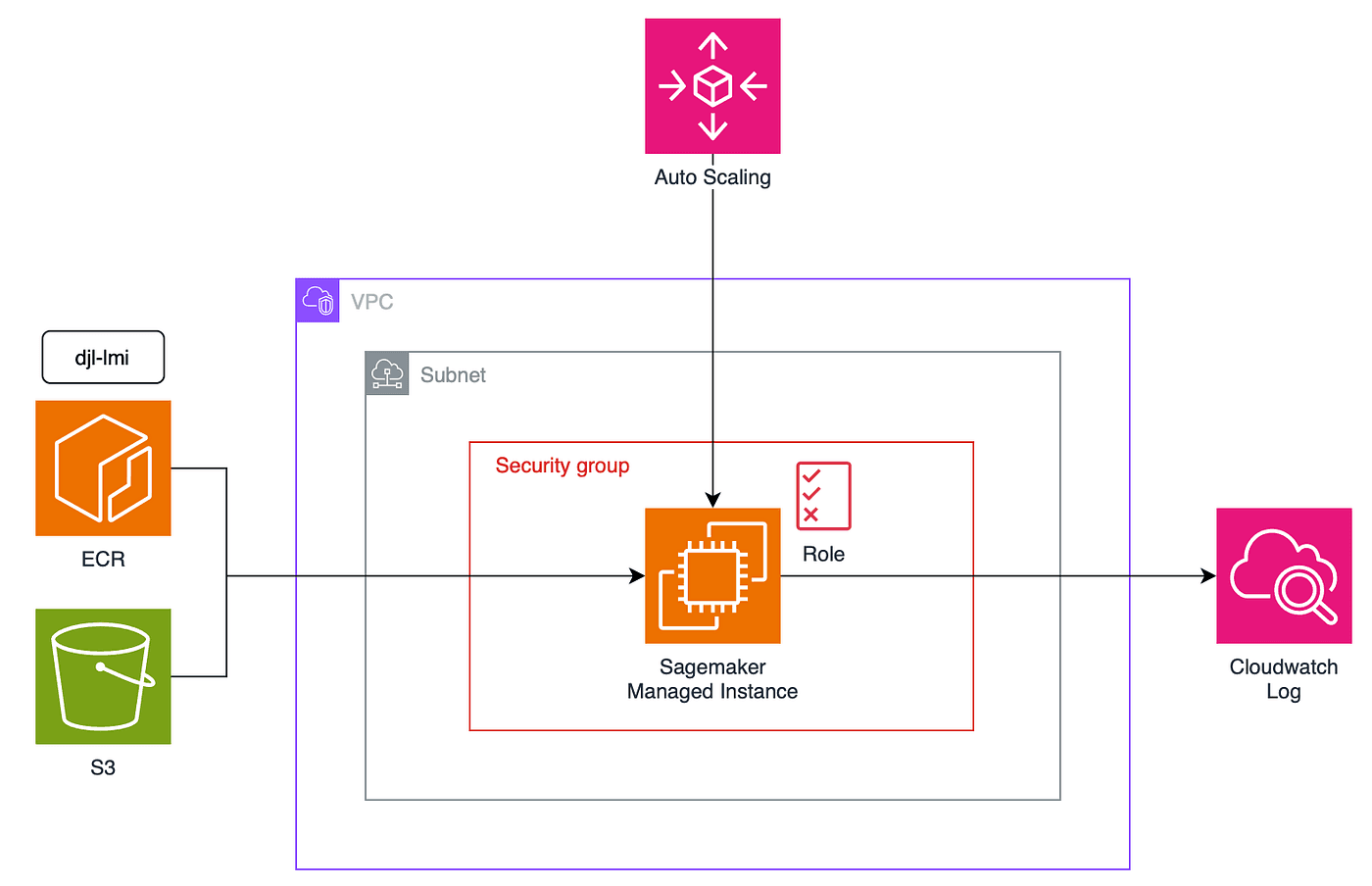
Amazon SageMaker AI now supports bidirectional streaming for real-time inference, enabling continuous two-way data flow between clients and model containers. Combined with vLLM's Realtime API, this allows developers to deploy speech-to-text models like Mistral AI's Voxtral-Mini-4B that process audio incrementally and return transcriptions in real time over WebSocket connections. The integration eliminates traditional request-response latency bottlenecks that break real-time voice applications like voice agents, live captioning, and contact center analytics.
TL;DR
- SageMaker AI bidirectional streaming (available since November 2025) enables persistent full-duplex connections between clients and inference containers using HTTP/2 protocol translation
- vLLM's Realtime API supports speech models that transcribe audio incrementally via WebSocket, with piecewise CUDA graph execution reducing per-token latency during streaming
- Mistral AI's Voxtral-Mini-4B-Realtime model can now be deployed on SageMaker endpoints as a fully managed speech-to-text service without custom infrastructure
- The combination eliminates vendor lock-in on the serving layer while removing undifferentiated heavy lifting around protocol translation and GPU optimization
Why It Matters
Real-time voice AI has been constrained by infrastructure limitations: traditional APIs require uploading complete audio before processing begins, adding unacceptable latency for interactive applications. This integration removes that constraint by providing native bidirectional streaming at the infrastructure layer while vLLM handles efficient incremental model execution. For a category of applications that demands sub-second responsiveness, this represents a meaningful shift from prototype-friendly to production-ready infrastructure.
Business Impact
Operators building voice agents, contact center solutions, or accessibility tools can now deploy production-grade speech-to-text without building custom streaming infrastructure or managing GPU optimization details. The fully managed SageMaker endpoint model reduces operational overhead while vLLM's open-source serving layer prevents vendor lock-in on the model serving side. This lowers the barrier to entry for voice AI applications while maintaining cost efficiency through optimized GPU utilization.
Key Implications
- Voice AI applications can now achieve real-time performance on managed infrastructure, expanding the addressable market beyond companies with deep infrastructure expertise
- Open-source vLLM integration on SageMaker creates a middle ground between fully managed proprietary services and self-managed deployment, appealing to operators who want control without operational burden
- The bidirectional streaming capability is not limited to speech models and could enable other streaming inference workloads that require persistent connections and low latency
What to Watch
Monitor adoption patterns to see whether this infrastructure combination becomes the standard for voice AI deployment or remains a niche offering. Watch for vLLM and SageMaker to expand bidirectional streaming support to other model types and use cases beyond speech. Track whether competing cloud providers (Google Cloud, Azure) introduce similar bidirectional streaming capabilities to remain competitive in the real-time inference space.
Subscribe to the newsletter
The latest stories and analysis, delivered to your inbox.
Free. No spam. Unsubscribe any time.