AWS Details Modular Voice Agent Design for Production Scale
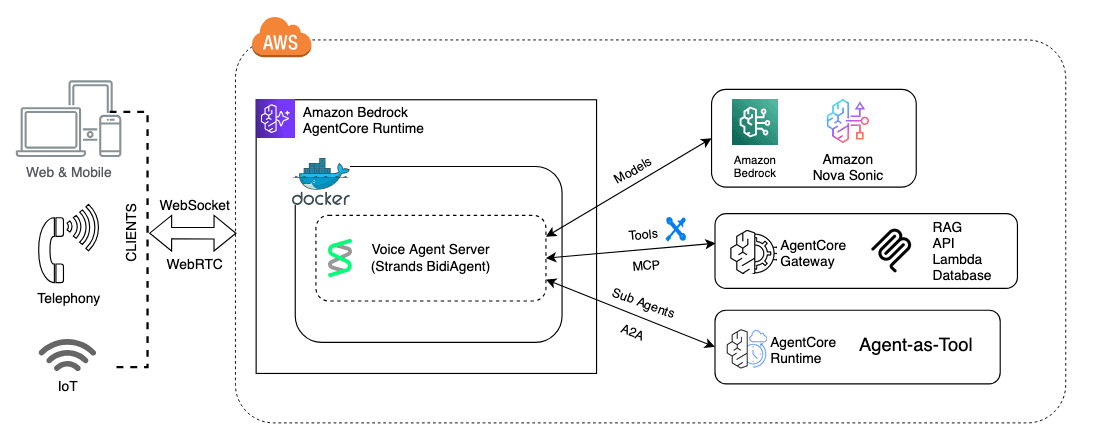
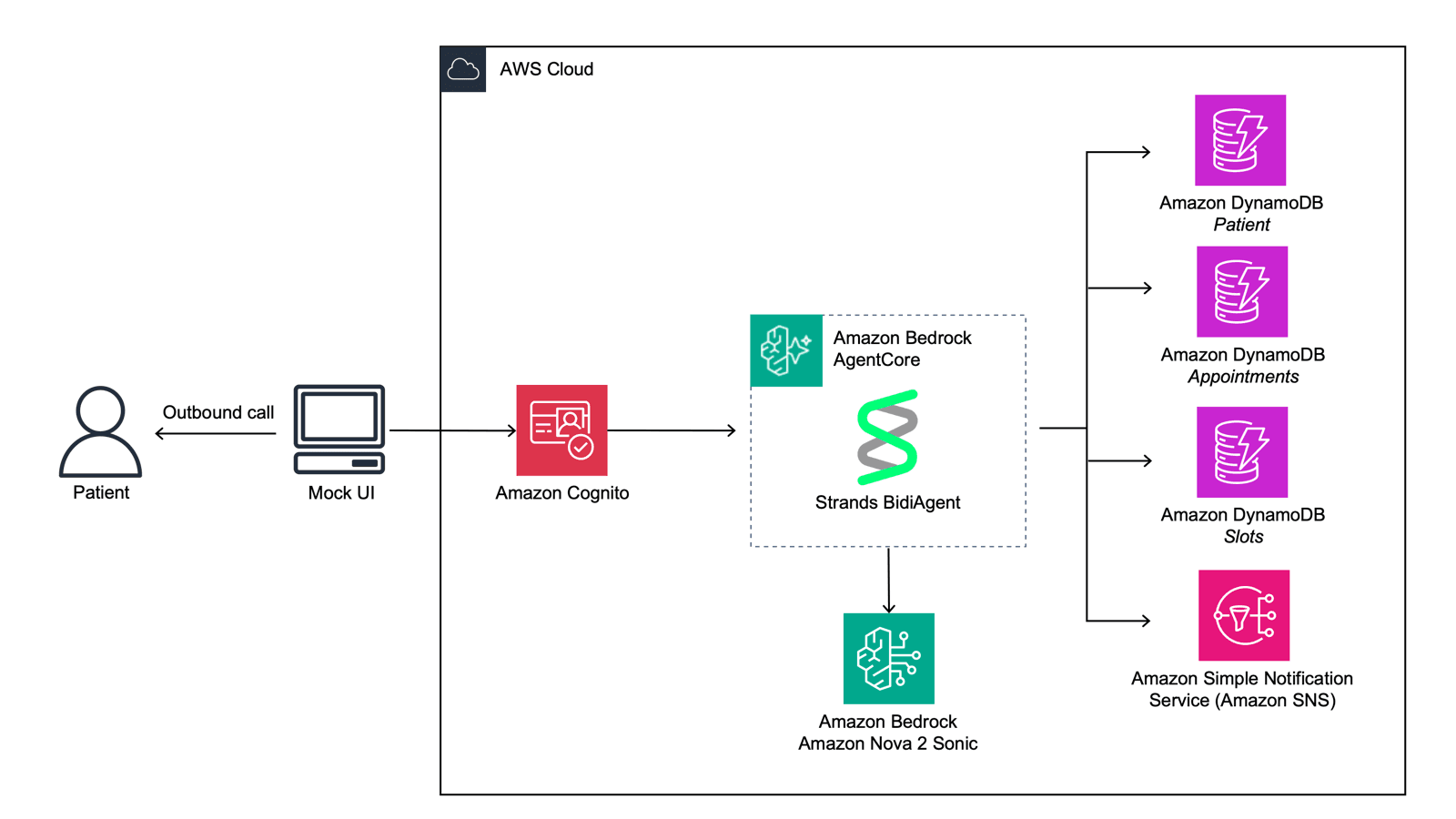
Amazon has published a technical guide on building scalable voice agents using Nova Sonic, a speech-to-speech foundation model, combined with Bedrock AgentCore Runtime and the open source Strands Agents framework. The post outlines three architectural patterns: tool-driven agents, sub-agents acting as tools, and session segmentation strategies that decompose large assistants into specialized, reusable components. The approach addresses common production challenges like latency, real-time audio management, and multi-agent coordination by leveraging serverless hosting, bidirectional WebSocket streaming, microVM-level isolation, and persistent memory across sessions.
TL;DR
- Amazon Nova Sonic enables natural speech-to-speech conversations with real-time understanding of tone and conversational flow
- Bedrock AgentCore Runtime provides serverless hosting with bidirectional WebSocket streaming, microVM isolation, and voice-specific telemetry like time-to-first-audio
- Three architectural patterns decompose voice agents into tool-driven agents, sub-agents as tools, and session segmentation for security and maintainability
- The stack supports shared tool hosting via Model Context Protocol (MCP) and persistent memory across sessions to reduce latency and improve responsiveness
Why It Matters
Voice agents are moving from monolithic designs to modular, composable architectures that isolate concerns and reduce latency. AWS is providing production-grade infrastructure and open source tooling to make this shift practical, addressing the real engineering challenges teams face when deploying voice AI at scale. This matters because voice interactions demand sub-second responsiveness and natural conversational flow, making architectural choices critical to user experience.
Business Impact
Organizations building customer-facing voice applications need to balance responsiveness, reliability, and cost. This guide shows how to use managed services and modular agent design to reduce engineering overhead while maintaining low latency and clear security boundaries. For teams evaluating voice AI platforms, it demonstrates a path to production that avoids building custom infrastructure for streaming, session management, and tool orchestration.
Key Implications
- Modular agent architectures with sub-agents and tools are becoming the standard for production voice systems, replacing monolithic approaches that struggle with latency and maintainability
- Serverless hosting with microVM-level isolation addresses the noisy-neighbor problem in shared infrastructure, critical for consistent voice response times
- Open source frameworks like Strands Agents lower the barrier to building voice agents on proprietary cloud infrastructure by providing a standard SDK interface
What to Watch
Monitor adoption of session segmentation and sub-agent patterns in production voice deployments to see if they become industry standard. Watch whether Model Context Protocol (MCP) gains traction as a standard for tool integration across voice agent platforms. Track latency metrics and time-to-first-audio benchmarks as teams deploy these patterns to understand real-world performance gains.
Subscribe to the newsletter
The latest stories and analysis, delivered to your inbox.
Free. No spam. Unsubscribe any time.