Pulse AI and Bedrock Cut Financial Document Processing From Days to Hours
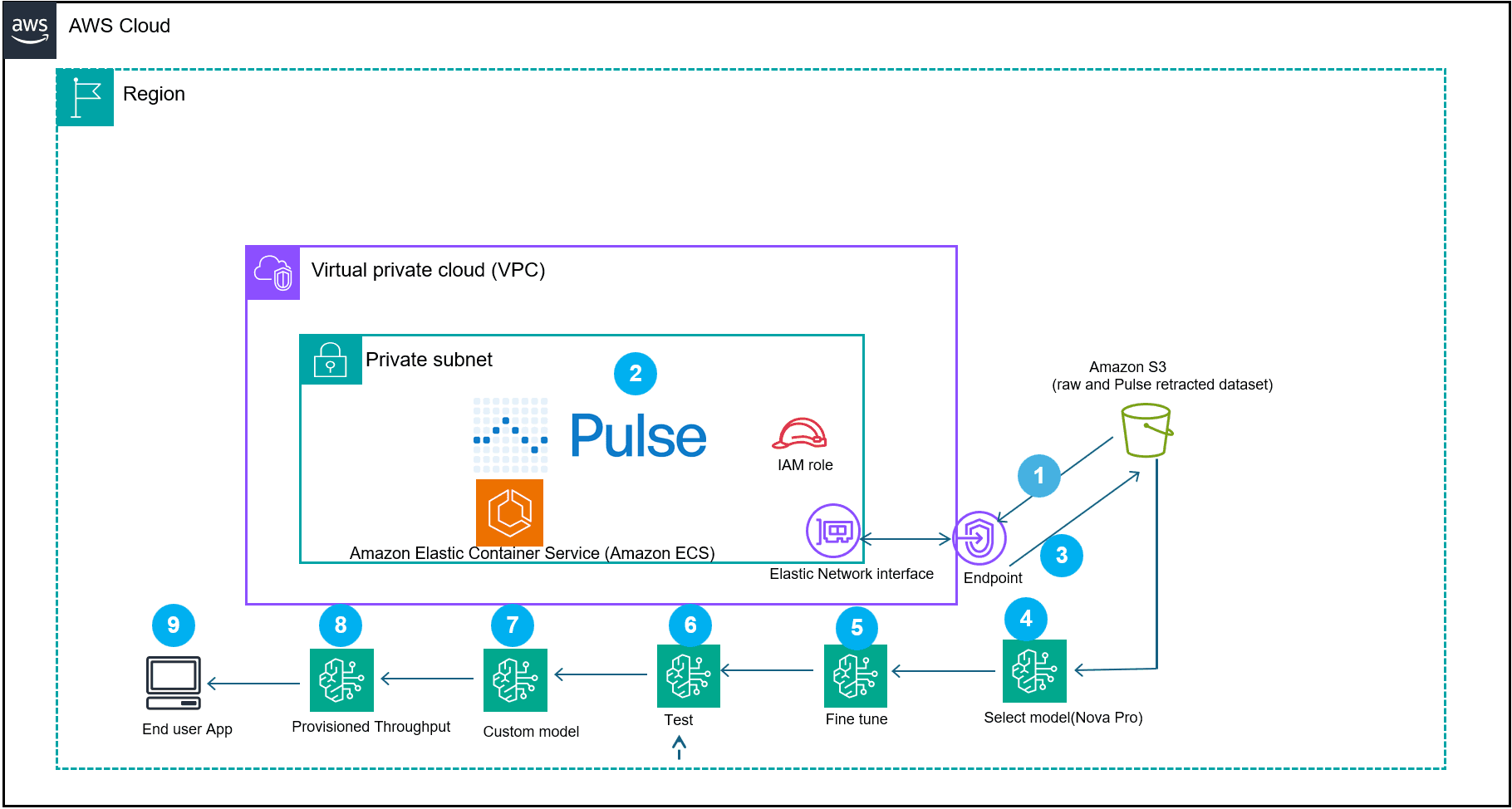
AWS and Pulse AI have demonstrated a financial document processing pipeline that combines Pulse's document understanding capabilities with Amazon Bedrock's fine-tuning infrastructure to extract structured data from complex financial documents like balance sheets and SEC filings. Traditional OCR tools fail on these documents because they miss structural relationships and hierarchical data, leading to cascading errors in downstream analytics. The combined approach enables organizations to process batches of 1,000 complex documents in hours rather than days, with custom models trained on organization-specific financial conventions reducing manual review significantly.
TL;DR
- Pulse AI integrates vision language models with classical ML to extract semantically-aware data from complex financial documents with intricate tables and multi-column layouts
- Amazon Bedrock fine-tunes Nova models on extracted data to create domain-specific financial intelligence without ML ops overhead
- One deployment processed 1,000 complex financial documents in under three hours versus multi-day turnaround with traditional methods
- Custom models reduce manual review cycles from days to hours by understanding organization-specific financial conventions and data relationships
Why It Matters
Financial document processing represents a high-value but error-prone use case where OCR mistakes cascade through interconnected calculations, making it a critical test bed for multimodal AI systems. This work demonstrates how combining specialized document understanding with fine-tuned LLMs can solve domain-specific problems that generic OCR and foundation models cannot handle alone, pointing toward a broader pattern of vertical AI solutions built on managed cloud infrastructure.
Business Impact
Financial institutions and private equity firms process massive volumes of documents daily, and processing speed directly impacts decision velocity and operational costs. Reducing multi-day document processing to hours while maintaining accuracy and auditability addresses a genuine bottleneck, particularly for organizations handling hundreds of thousands of documents annually across compliance, analytics, and due diligence workflows.
Key Implications
- Managed fine-tuning services like Bedrock reduce friction for enterprises to deploy custom models without building ML infrastructure, accelerating adoption of domain-specific AI solutions
- Hybrid approaches combining specialized document understanding tools with general-purpose LLMs may outperform end-to-end foundation model approaches for structured data extraction tasks
- Financial services and other regulated industries increasingly require auditable, traceable AI pipelines, creating demand for solutions that produce structured outputs rather than opaque text generation
What to Watch
Monitor whether this pattern spreads to other document-heavy industries like healthcare, legal, and insurance, and whether AWS and competitors expand managed fine-tuning offerings to support more vertical use cases. Also track whether Pulse's approach of combining vision models with classical ML becomes a standard architecture for document processing or if pure foundation model approaches catch up on accuracy and cost.
Subscribe to the newsletter
The latest stories and analysis, delivered to your inbox.
Free. No spam. Unsubscribe any time.


