AWS, Databricks Show How to Fine-Tune LLMs Without Bypassing Data Governance
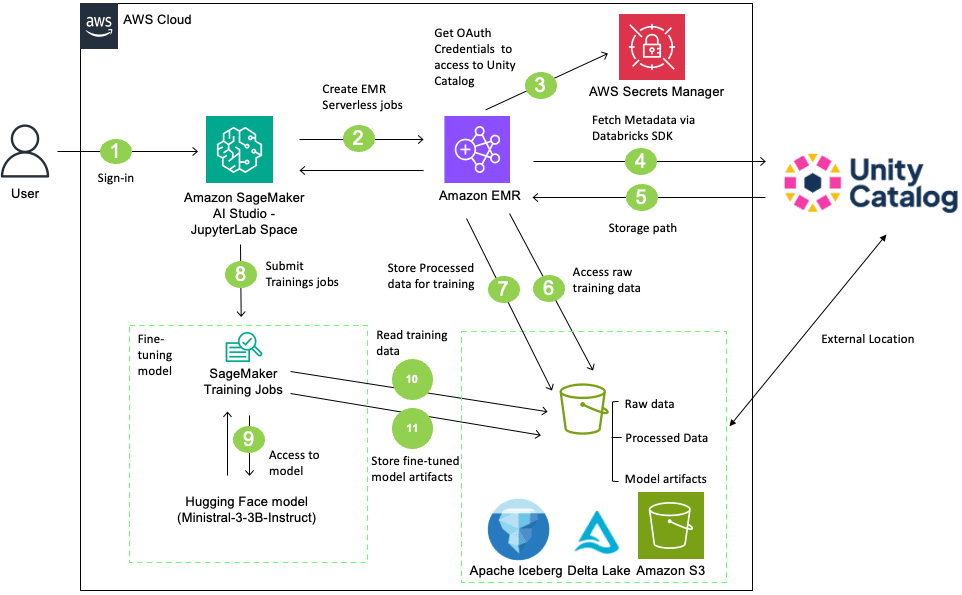
AWS and Databricks have published a reference architecture for fine-tuning large language models while maintaining data governance through Databricks Unity Catalog. The workflow integrates SageMaker AI Training with Unity Catalog's permission controls, uses Amazon EMR Serverless for data preprocessing, and tracks lineage from source data through model artifacts. This addresses a real compliance gap: without structured integration, SageMaker jobs can bypass Unity Catalog's authorization model when accessing S3 data, creating audit and regulatory exposure in production environments.
TL;DR
- AWS published a reference implementation for fine-tuning LLMs with SageMaker AI while preserving Databricks Unity Catalog governance controls
- The solution uses EMR Serverless for Spark-based preprocessing and maintains data lineage tracking across the entire workflow
- Key problem solved: SageMaker Training jobs can inadvertently bypass Unity Catalog's fine-grained authorization, creating compliance and audit gaps
- Demonstrates fine-tuning of Ministral-3-3B-Instruct model with proper data governance for regulated industries and production workloads
Why It Matters
As enterprises adopt multi-cloud ML stacks, governance gaps between data platforms and training services create real compliance risk. This pattern shows how to maintain centralized data governance while using best-in-class ML services, which is critical for regulated industries where audit trails and permission enforcement cannot be bypassed or circumvented.
Business Impact
For operators running production ML workloads, this solves a concrete operational problem: how to fine-tune models without losing visibility into which data trained which models or creating compliance exposure. Teams using both Databricks and AWS can now integrate these services without choosing between governance and capability.
Key Implications
- Structured integration patterns between data governance platforms and ML training services are becoming table stakes for enterprise adoption
- Data lineage tracking across heterogeneous services is moving from nice-to-have to compliance requirement in regulated industries
- The reference architecture suggests AWS and Databricks are positioning their services as complementary rather than competitive in the ML stack
What to Watch
Monitor whether this pattern becomes a standard practice across other cloud providers and whether similar integrations emerge for other governance platforms. Watch for adoption signals in regulated industries like finance and healthcare, where compliance requirements drive architectural decisions.
Subscribe to the newsletter
The latest stories and analysis, delivered to your inbox.
Free. No spam. Unsubscribe any time.



