AWS Maps Foundation Model Scaling Across Training, Post-Training, and Inference
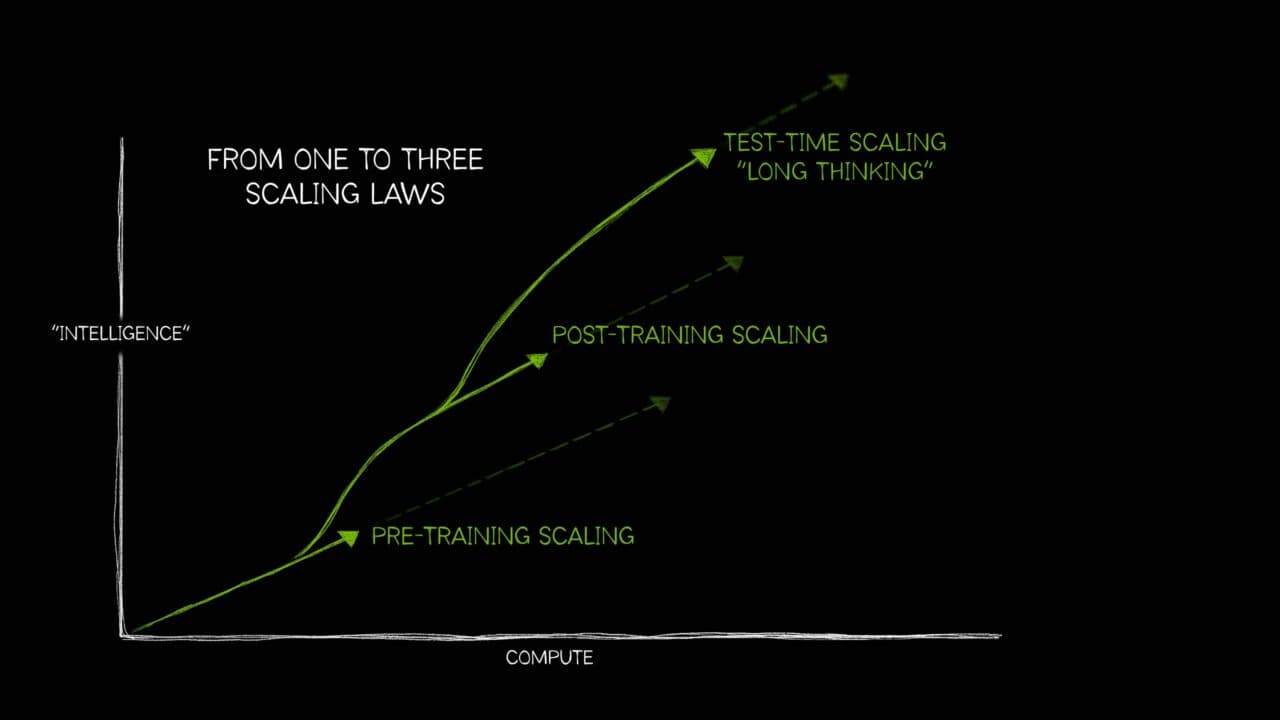
AWS and collaborators have published a technical framework for understanding how foundation model training and inference workloads map to cloud infrastructure and open-source software stacks. The post argues that scaling has evolved beyond pre-training alone, now encompassing post-training (fine-tuning, reinforcement learning) and test-time compute, which converge on similar infrastructure needs: tightly coupled accelerators, high-bandwidth low-latency networking, distributed storage, and robust observability. The analysis layers hardware infrastructure, resource orchestration (Slurm, Kubernetes), ML frameworks (PyTorch, JAX), and monitoring tools (Prometheus, Grafana) to help engineers diagnose bottlenecks and optimize large-scale distributed systems.
TL;DR
- Scaling laws for foundation models now span three regimes: pre-training, post-training (SFT and RL), and test-time compute, each with distinct infrastructure demands
- AWS infrastructure components (multi-node accelerators, networking, distributed storage) must integrate tightly with open-source stacks (Slurm, Kubernetes, PyTorch, JAX, Prometheus, Grafana)
- The foundation model lifecycle requires convergent infrastructure: tightly coupled compute, high-bandwidth low-latency networks, distributed storage backends, and cluster-wide observability
- This is the first in a series examining how AWS building blocks map to each layer of the OSS stack for training and inference at scale
Why It Matters
Foundation model development has moved beyond the simple 'more compute equals better results' paradigm. Understanding how pre-training, post-training, and inference workloads interact with infrastructure is now critical for practitioners building at scale. This framework helps engineers reason about system bottlenecks and resource allocation across the entire model lifecycle, not just training.
Business Impact
For operators and founders building or deploying foundation models, infrastructure costs and efficiency directly impact unit economics. A clear mental model of how OSS frameworks and cloud infrastructure interact enables better capacity planning, faster iteration, and more predictable scaling costs. This is especially relevant as post-training and inference become competitive advantages.
Key Implications
- Infrastructure decisions must account for all three scaling regimes, not just pre-training, shifting how teams budget and provision resources
- Observability and orchestration tooling are now as critical as raw compute capacity, requiring investment in monitoring and cluster management
- Open-source software stacks have become the de facto standard, making AWS's ability to integrate with Slurm, Kubernetes, PyTorch, and other tools a key competitive factor
What to Watch
Monitor how AWS evolves its managed services for resource orchestration and observability in the context of multi-regime scaling. Watch whether other cloud providers publish similar technical frameworks and how they position their infrastructure advantages. Track whether the convergence of infrastructure requirements across pre-training, post-training, and inference leads to new hardware or software abstractions.
Subscribe to the newsletter
The latest stories and analysis, delivered to your inbox.
Free. No spam. Unsubscribe any time.



