AWS Automates Schema Generation for Document Processing
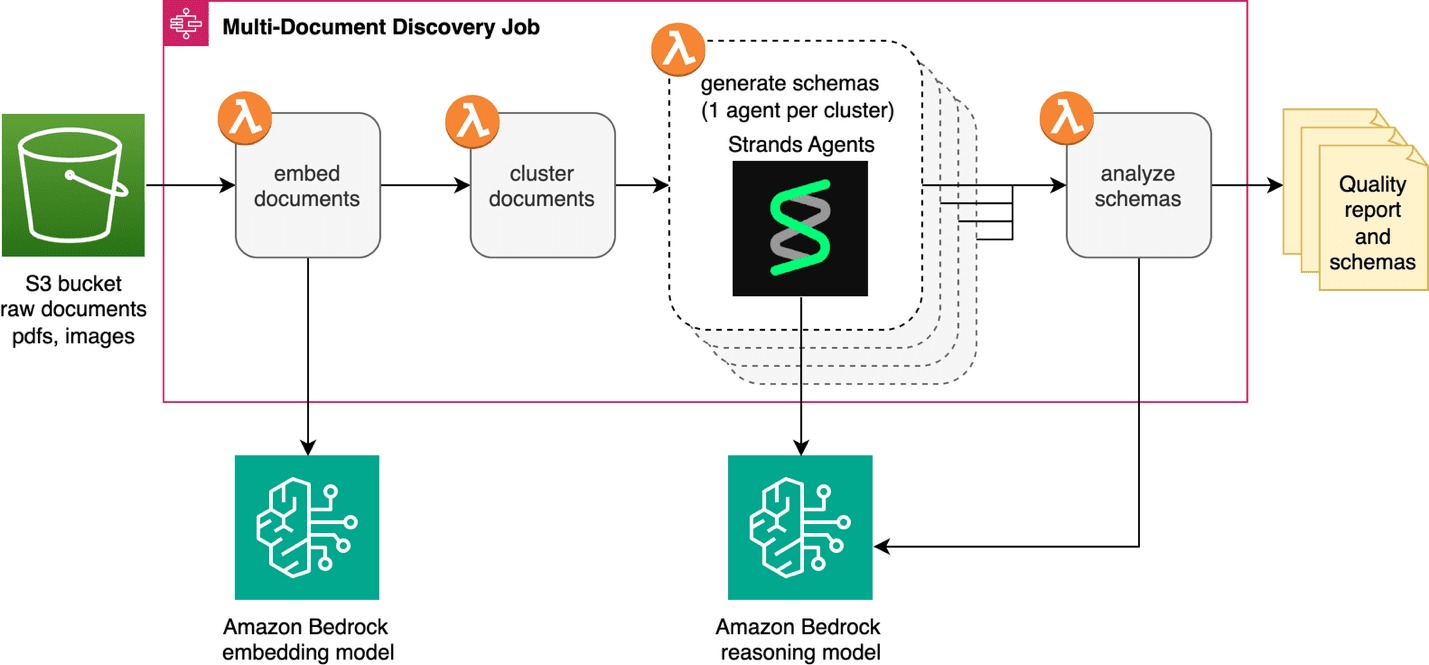
AWS has added automated schema generation to its IDP Accelerator, a serverless document processing solution. The new multi-document discovery feature analyzes unlabeled document collections, clusters them by type using visual embeddings, and generates extraction schemas automatically. This removes the manual bottleneck of identifying document classes and creating schemas before deploying intelligent document processing at scale.
TL;DR
- AWS IDP Accelerator now includes multi-document discovery that automatically clusters unknown documents and generates extraction schemas
- Uses visual embeddings for automatic document clustering and AI agents for schema generation
- Eliminates the prerequisite of knowing document classes upfront, reducing manual effort for large-scale IDP deployments
- Integrated into existing Discovery Module alongside single-document capability, processing documents from S3 or Zip uploads
Why It Matters
Document classification and schema definition have been a significant friction point in deploying intelligent document processing at scale. Automating this discovery phase addresses a real operational bottleneck: organizations with thousands of unlabeled documents previously had to manually identify document types and define extraction fields before any IDP system could work. This capability makes IDP initiatives more feasible for enterprises with heterogeneous document collections.
Business Impact
For operators and founders building document processing workflows, this reduces time-to-value and lowers the expertise barrier. Instead of requiring domain experts to manually classify documents and define schemas, teams can upload a collection and get structured extraction schemas ready for deployment. This is particularly valuable for industries like financial services, healthcare, and legal where document volume is high but document types may not be well-cataloged.
Key Implications
- Automated schema generation could accelerate adoption of IDP solutions by reducing upfront manual work and making business cases easier to justify
- Visual embedding-based clustering suggests the solution handles document layout and structure, not just text content, which is important for real-world document diversity
- Integration into an open-source accelerator means the capability is accessible to organizations already using AWS infrastructure, lowering switching costs
What to Watch
Monitor whether this capability handles edge cases well, such as documents with mixed layouts, poor image quality, or unusual structures. Also watch for adoption patterns to see if automated schema generation actually reduces manual refinement work in practice or if users still need significant schema tuning post-generation.
Subscribe to the newsletter
The latest stories and analysis, delivered to your inbox.
Free. No spam. Unsubscribe any time.



