Amazon Nova Multimodal Embeddings Unlock Cross-Modal Search for Manufacturing Docs
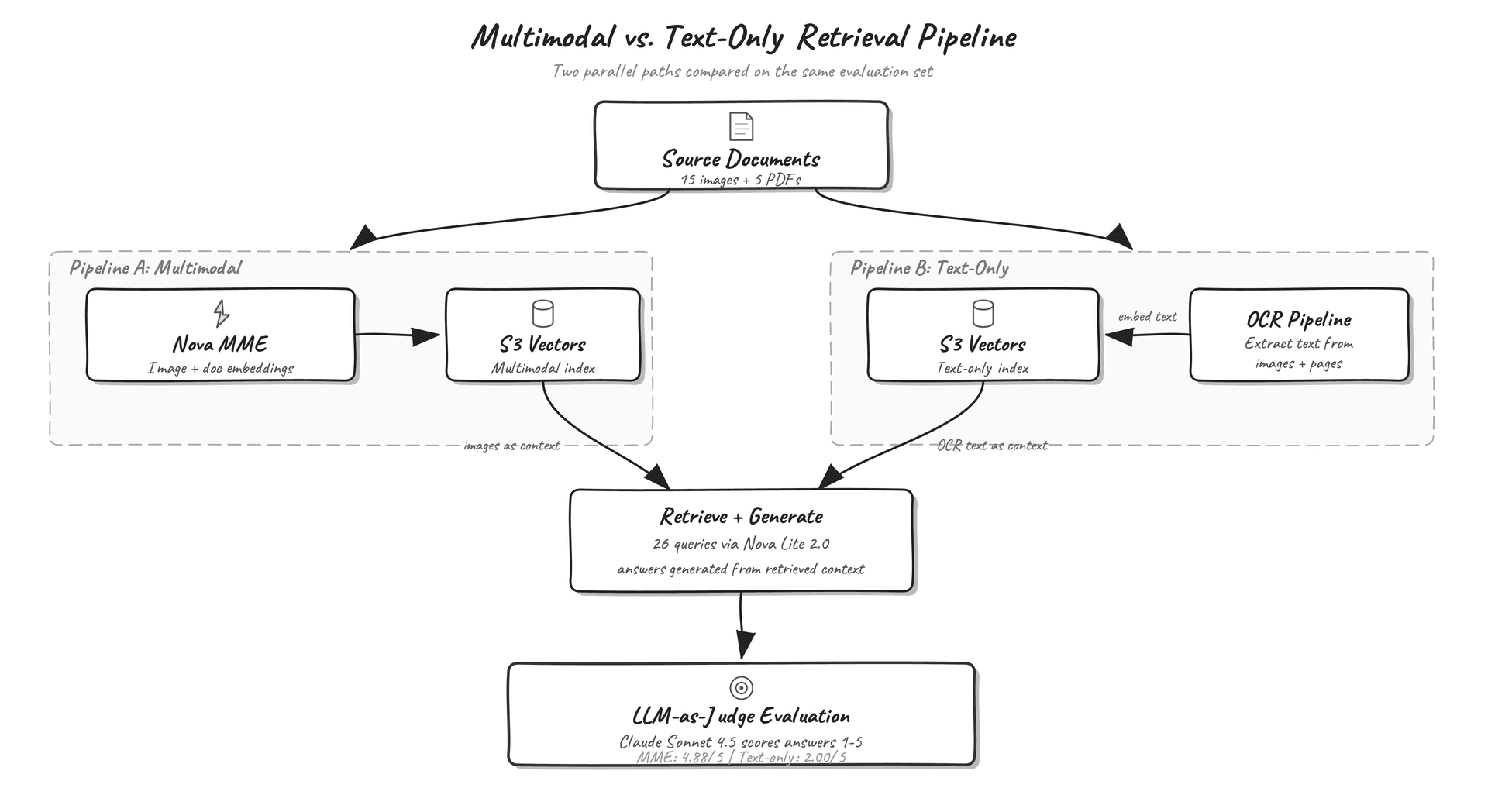
Amazon has released Nova Multimodal Embeddings, a model that maps text, images, and document pages into a shared vector space, enabling cross-modal retrieval where text queries can surface engineering diagrams and image queries can retrieve written specifications. The post demonstrates the system on aerospace manufacturing documents, showing how multimodal embeddings overcome the limitations of text-only retrieval systems that miss spatial relationships in diagrams, visual patterns in inspection images, and quantitative information in plots and charts. This addresses a concrete pain point in manufacturing, where technical repositories combine specifications, CAD drawings, photographs, and analysis plots that text-only OCR-based systems cannot effectively search.
TL;DR
- Amazon Nova Multimodal Embeddings projects text, images, and documents into a single vector space, enabling cross-modal search and retrieval
- Text-only retrieval systems fail on manufacturing documents because they miss visual information like torque tables in drawings, thermal contour plots, and spatial relationships in diagrams
- The approach processes images directly rather than converting them to text via OCR, preserving visual context and enabling a text query to match against an engineering diagram based on semantic understanding
- AWS evaluated the system on 26 manufacturing queries and compared generation quality between text-only and multimodal pipelines
Why It Matters
Multimodal embeddings represent a practical step forward in retrieval-augmented generation for document-heavy domains where information is distributed across text and visual content. Most enterprise knowledge repositories combine multiple modalities, but existing retrieval systems treat images as secondary or convert them to lossy text representations. This work demonstrates that shared embedding spaces can unlock information that text-only systems systematically miss.
Business Impact
Manufacturing, aerospace, and automotive companies maintain massive technical document repositories that are difficult to search effectively. Multimodal retrieval can reduce the time engineers spend hunting through specifications and diagrams, improve compliance and quality processes by surfacing relevant inspection images and test data, and enable faster onboarding by making institutional knowledge more discoverable. This directly impacts operational efficiency and risk management in capital-intensive industries.
Key Implications
- Multimodal embeddings shift the economics of document retrieval in technical domains, making it feasible to index and search visual content without manual annotation or text extraction
- Organizations with mixed-modality document repositories can now build retrieval systems that match the way engineers actually work, combining text queries with visual inspection and cross-referencing
- The shared vector space approach enables new query patterns, such as using an inspection photograph to find related specifications or using a thermal plot to retrieve design constraints, expanding the surface area of discoverable information
What to Watch
Monitor adoption rates in manufacturing and aerospace to understand whether multimodal retrieval becomes standard practice for technical document systems. Watch for extensions to other document-heavy domains like healthcare, legal, and scientific research where similar multimodal challenges exist. Also track whether competitors release comparable multimodal embedding models and how they compare on domain-specific benchmarks.
Subscribe to the newsletter
The latest stories and analysis, delivered to your inbox.
Free. No spam. Unsubscribe any time.


