Halliburton cuts seismic workflow setup time by 95% with Bedrock AI
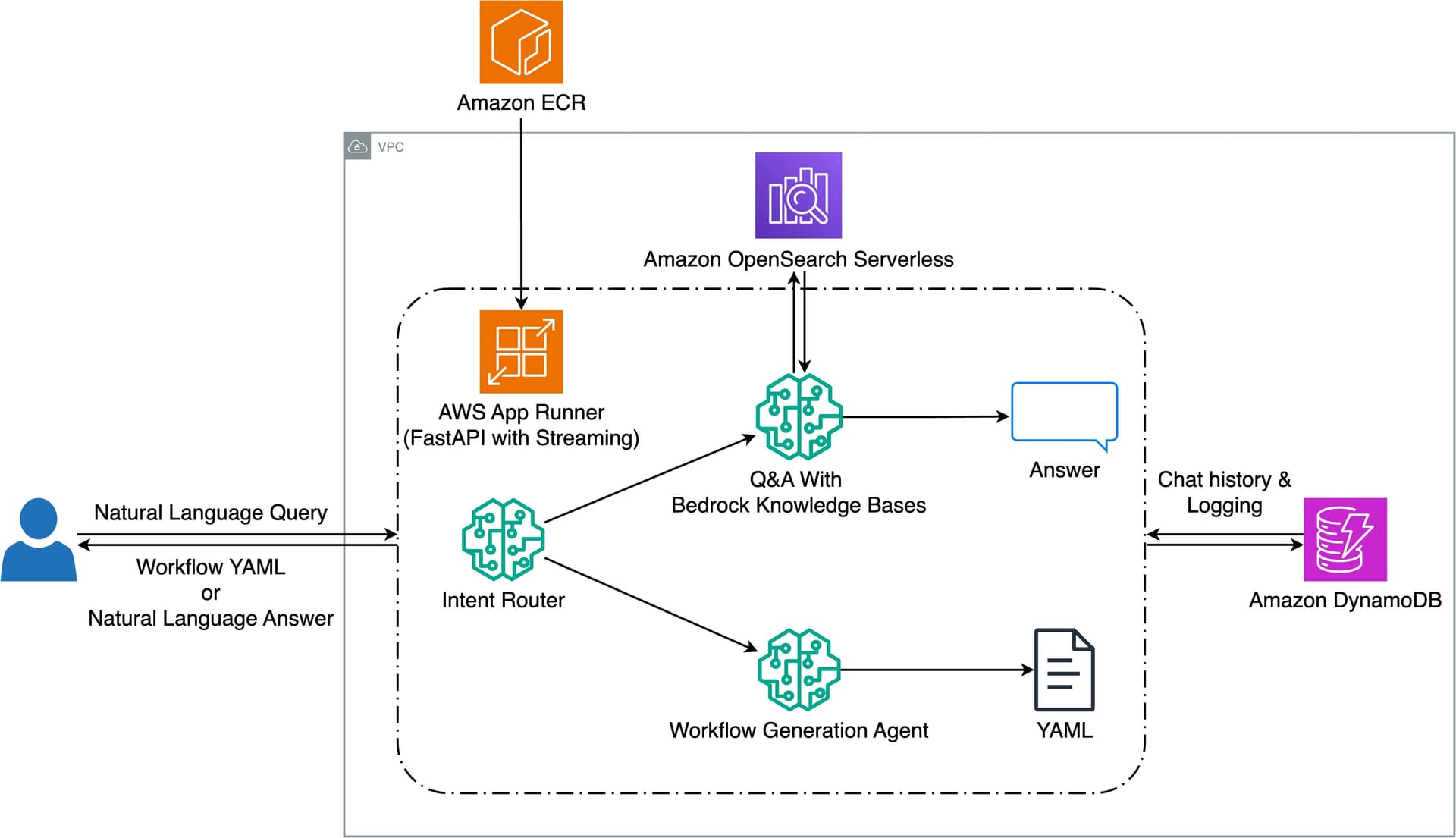
Halliburton partnered with AWS to build an AI-powered assistant for its Seismic Engine, a cloud-native application for seismic data processing. The solution uses Amazon Bedrock, Amazon Nova, and related AWS services to convert natural language queries into executable seismic workflows, replacing a manual process that required configuring approximately 100 specialized tools. The system achieved workflow acceleration of up to 95% and makes complex geophysical tools more accessible to a broader range of users.
TL;DR
- Halliburton deployed an AI assistant for Seismic Engine using Amazon Bedrock and Amazon Nova to automate workflow creation
- Geoscientists can now configure processing tools through natural language conversation instead of manual configuration of 100+ specialized tools
- The solution achieved up to 95% workflow acceleration and includes a Q&A system for Seismic Engine documentation
- Architecture uses FastAPI on AWS App Runner, Amazon DynamoDB for chat history, and Amazon OpenSearch Serverless for knowledge retrieval
Why It Matters
This demonstrates how generative AI can meaningfully reduce friction in specialized technical domains by converting complex configuration tasks into conversational interfaces. The 95% acceleration metric suggests that LLM-powered assistants can deliver substantial productivity gains when applied to well-defined, tool-heavy workflows, which has implications for how enterprises approach automation of expert-level tasks.
Business Impact
For energy companies and operators, reducing workflow configuration time by an order of magnitude directly improves project velocity and lowers the expertise barrier for using advanced geophysical tools. This pattern is replicable across other capital-intensive industries with complex technical workflows, making it relevant for founders building AI solutions for enterprise verticals.
Key Implications
- Generative AI can accelerate domain-specific workflows by 10x or more when paired with proper knowledge retrieval and intent routing, suggesting broad applicability beyond energy
- Cloud-native architecture with serverless components enables scalable AI assistants without requiring significant infrastructure investment from enterprises
- Intent routing and multi-turn conversation support are critical for production systems that need to handle both workflow generation and documentation queries
What to Watch
Monitor whether Halliburton expands this pattern to other Landmark products and whether similar acceleration metrics hold across different tool sets and user expertise levels. Track adoption rates among geoscientists to understand whether the accessibility gains translate to actual usage and whether the system requires ongoing fine-tuning or knowledge base updates.
Subscribe to the newsletter
The latest stories and analysis, delivered to your inbox.
Free. No spam. Unsubscribe any time.



