AWS Details Verifiable Rewards Method for More Reliable LLM Training
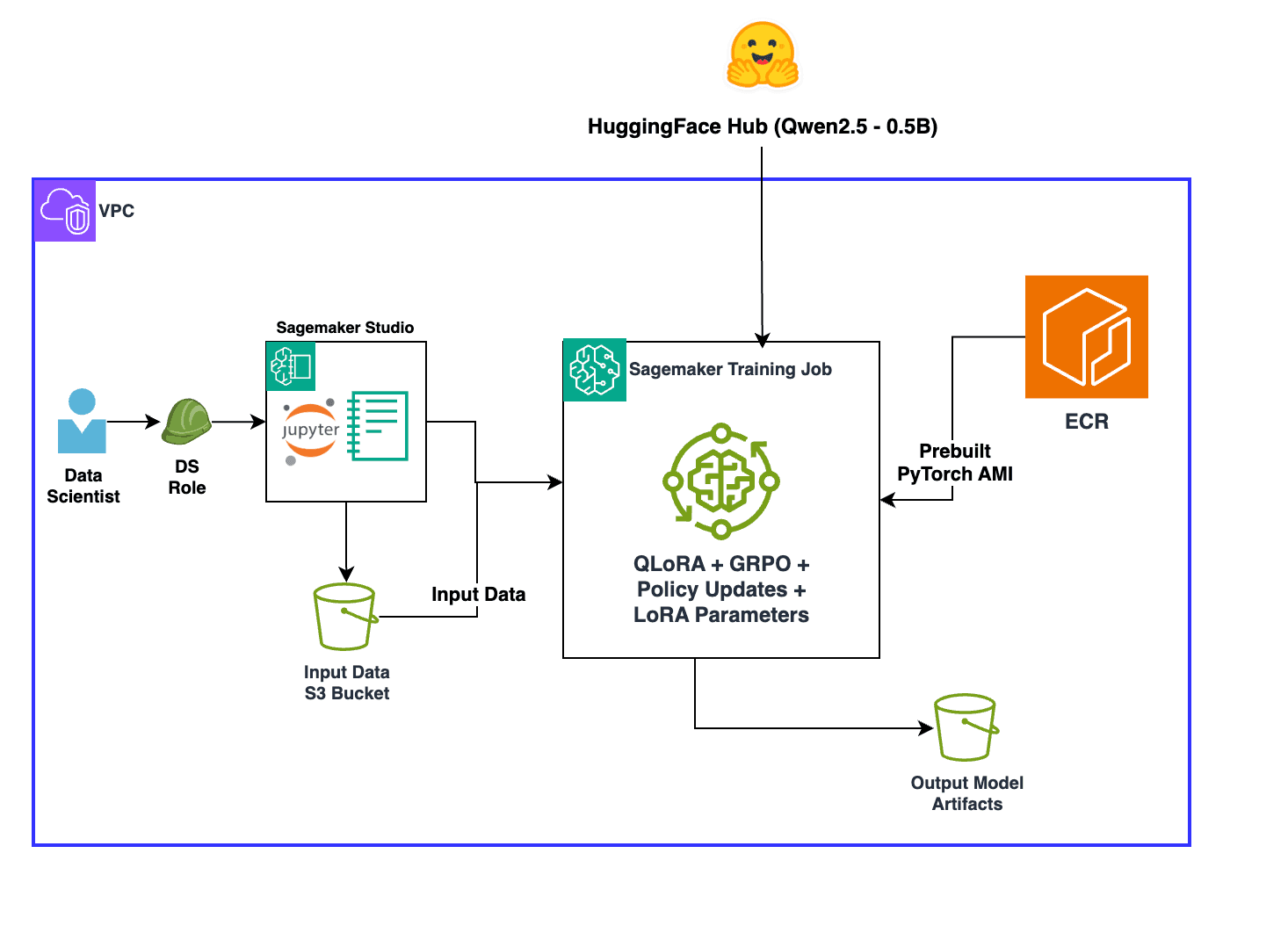
AWS published a technical guide on reinforcement learning with verifiable rewards (RLVR), a method that addresses reward signal reliability in LLM training by using rule-based, programmatic feedback instead of subjective human ratings. The approach combines RLVR with Group Relative Policy Optimization (GRPO), which optimizes performance across distinct task categories rather than globally, reducing training variance and improving convergence. The guide demonstrates the technique on math problem solving using the GSM8K dataset, though the methods apply broadly to tasks with objectively verifiable outputs like code generation and symbolic reasoning.
TL;DR
- RLVR uses automated, rule-based reward functions to eliminate reward hacking and human rating bottlenecks in RL training
- GRPO organizes training data into groups and optimizes relative to each group's baseline, improving consistency across categories
- Combining RLVR and GRPO enables rapid iteration and adaptation to evolving requirements without retraining from scratch
- The approach works best for tasks with objective verification criteria, such as math, code generation, and symbolic manipulation
Why It Matters
Reward signal quality is a fundamental constraint in modern LLM training. Poor reward functions lead to reward hacking and unpredictable model behavior, while human-rated feedback is slow and expensive to scale. RLVR and GRPO offer a practical path to more reliable, faster training loops by automating feedback and balancing performance across task dimensions, addressing a core bottleneck in production LLM development.
Business Impact
For teams training or fine-tuning LLMs at scale, this approach reduces the cost and latency of collecting training feedback while improving model consistency. Organizations can iterate faster on evolving requirements and adapt models to new domains without expensive human annotation campaigns, making it relevant for any company building production AI systems.
Key Implications
- Programmatic reward functions shift RL training from human-dependent feedback loops to automated, reproducible scoring, enabling faster iteration cycles
- Group-relative optimization suggests that balancing performance across task categories may be more effective than global optimization, with implications for how models generalize
- The technique is domain-specific, working well for verifiable tasks but not applicable to subjective domains like content moderation or creative writing
What to Watch
Monitor adoption of RLVR and GRPO in production LLM training pipelines, particularly among companies training models on code and reasoning tasks. Watch for open-source implementations and whether other cloud providers or model labs adopt similar verification-based approaches. Also track whether the technique extends effectively to domains beyond math and code, or if it remains limited to objectively verifiable tasks.
Subscribe to the newsletter
The latest stories and analysis, delivered to your inbox.
Free. No spam. Unsubscribe any time.



