LLMsNews
Speculative Decoding on Trainium Cuts LLM Inference Latency 3x
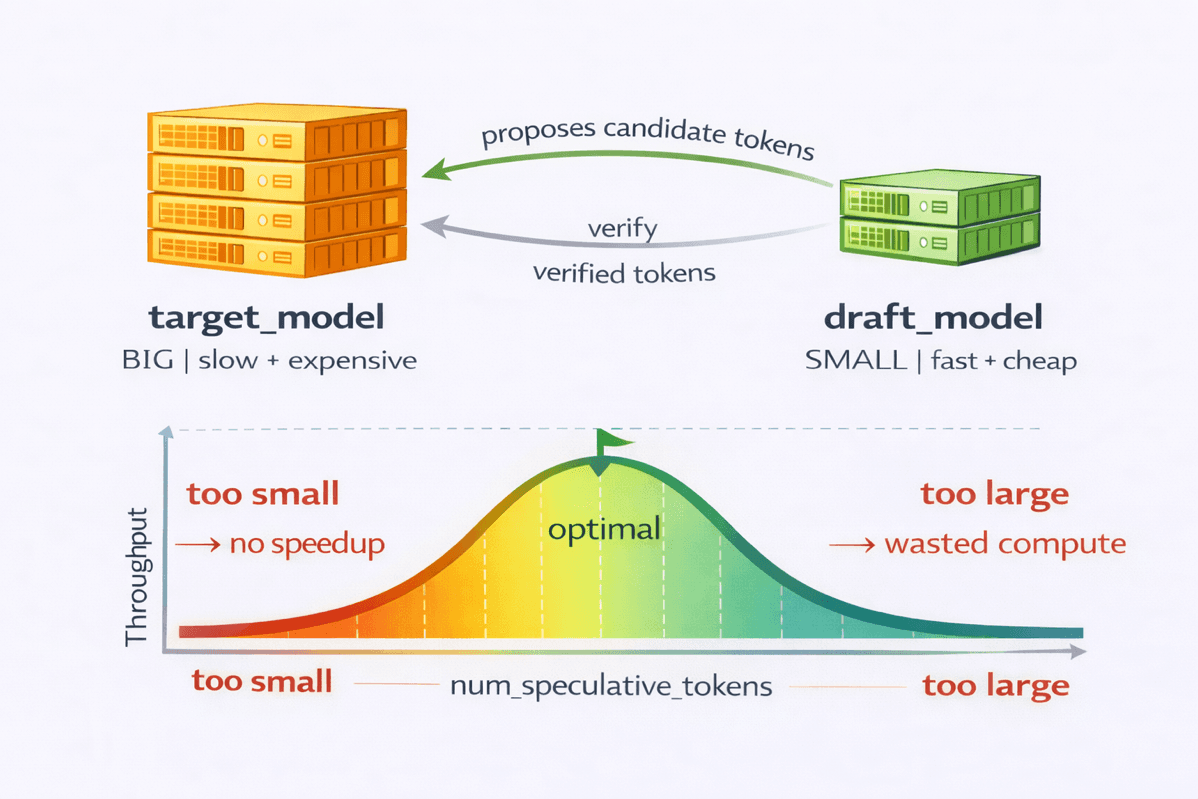
AWS and vLLM have demonstrated that speculative decoding on Trainium chips can accelerate token generation by up to 3x for decode-heavy LLM workloads. The technique uses a small draft model to propose multiple tokens at once, which a larger target model verifies in a single forward pass, reducing sequential decode steps and lowering per-token inference costs. The post provides benchmarks using Qwen3 models, practical tuning guidance for draft model selection and speculative token window sizing, and reproducible instructions for deployment on Kubernetes.
by Yahav Biran· AWS Machine Learning Blog
Source