Loka Cuts Voice AI Latency with Amazon Nova 2 Sonic
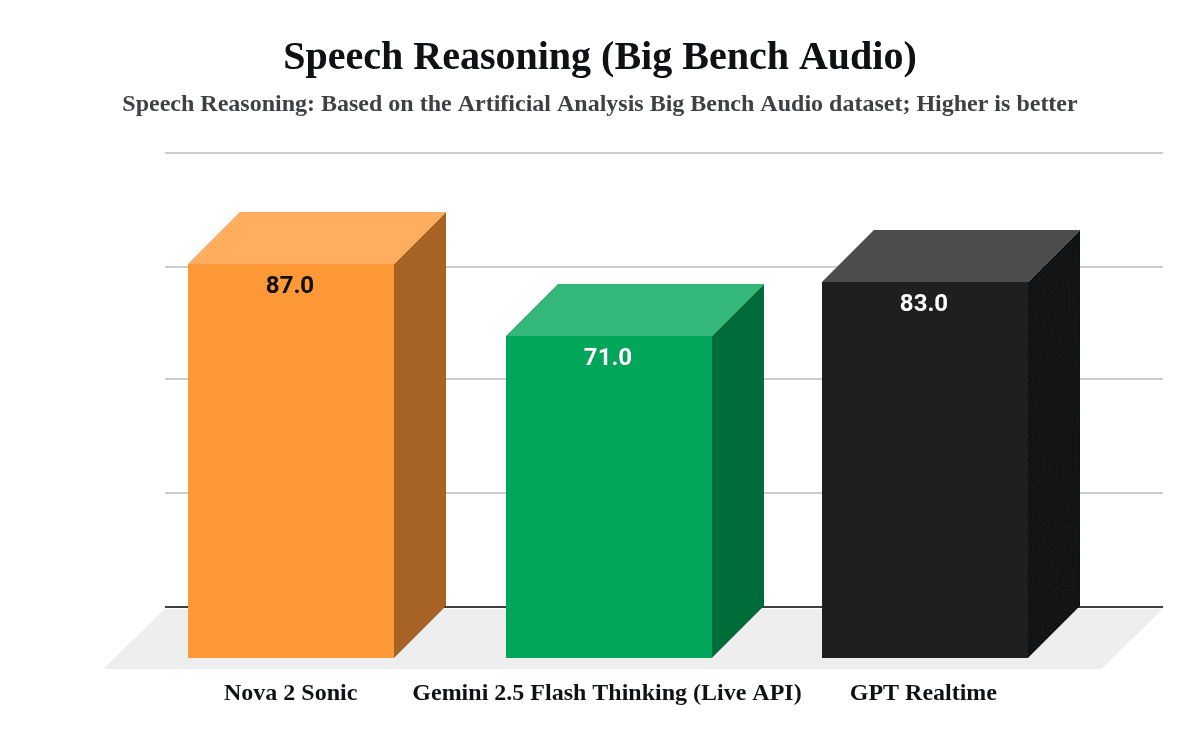
Loka built a voice AI agent using Amazon Nova 2 Sonic that processes audio end-to-end rather than converting speech to text and back, reducing response latency from 3-5 seconds to near-real-time while lowering costs. The approach achieved a speech reasoning score of 87.0 on Big Bench Audio, outperforming Google's Gemini 2.5 Flash (71.0) and OpenAI's GPT Realtime (83.0). The solution addresses a core frustration with traditional voice assistants: robotic, slow responses that damage customer experience and increase support costs.
TL;DR
- Loka deployed Amazon Nova 2 Sonic for native speech-to-speech processing, eliminating the traditional three-step pipeline (speech-to-text, LLM, text-to-speech) that introduces 3-5 second delays
- Amazon Nova 2 Sonic scored 87.0 on Big Bench Audio speech reasoning benchmark, outperforming Gemini 2.5 Flash Native Audio (71.0) and GPT Realtime (83.0)
- Native audio processing preserves tone, emotion, and subtle cues lost in text conversion, improving handling of complex requests like negation and scheduling constraints
- End-to-end audio approach reduces costs at scale while enabling faster, more natural conversational experiences for customer-facing applications like automotive dealership support
Why It Matters
Voice AI has struggled with latency and cost at scale, making it impractical for many customer service applications. Native speech-to-speech models sidestep the compounding delays of traditional pipelines by processing audio directly, capturing nuance that text-based systems lose. This represents a fundamental shift in how conversational AI can be deployed for real-time customer interactions.
Business Impact
Slow voice assistants drive customers to hang up, damaging brand reputation and increasing support costs. Loka's approach delivers faster response times and lower operational costs, making voice AI economically viable for businesses serving thousands of locations. The performance advantage on benchmarks suggests native audio models can handle complex customer requests more accurately than traditional systems.
Key Implications
- Native speech-to-speech models may become the standard for customer-facing voice applications, displacing traditional multi-step pipelines that introduce latency and information loss
- Cost efficiency at scale could accelerate voice AI adoption across industries like automotive, retail, and customer support where real-time responsiveness is critical
- Benchmark performance differences between models (Amazon Nova 2 Sonic at 87.0 vs competitors at 71-83) will likely influence enterprise purchasing decisions for voice AI infrastructure
What to Watch
Monitor adoption rates of native speech-to-speech models across customer service platforms and whether latency improvements translate to measurable business outcomes like reduced call abandonment. Track whether other cloud providers release competing native audio models and how pricing evolves as the technology matures. Watch for real-world accuracy and cost data from Loka and other early adopters to validate benchmark performance claims.
Subscribe to the newsletter
The latest stories and analysis, delivered to your inbox.
Free. No spam. Unsubscribe any time.



