OpenEnv Shifts to Community Governance for Open Source Agents
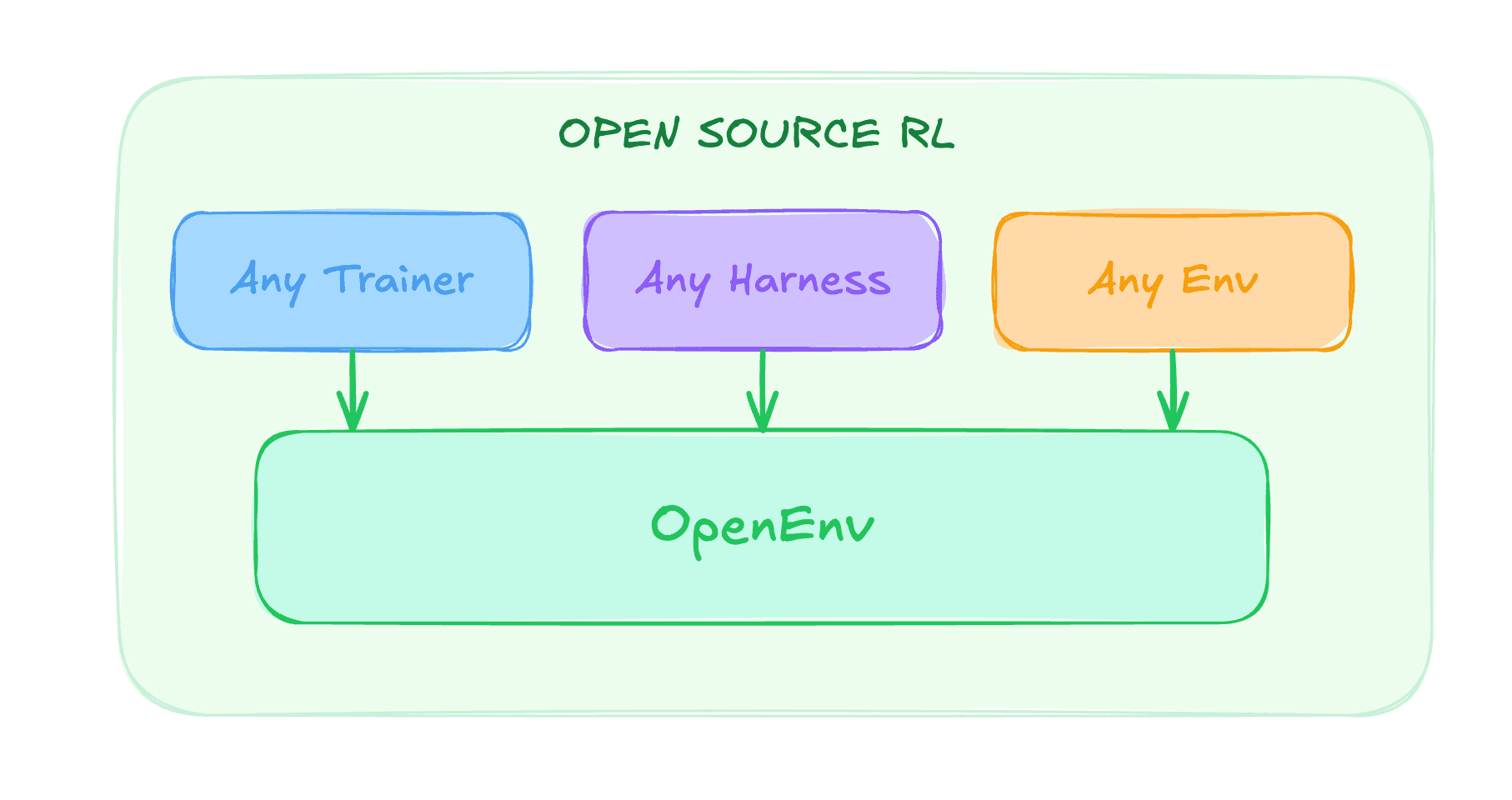
OpenEnv, a tool for building agentic execution environments, is transitioning to community governance with a steering committee that includes Meta, Nvidia, Hugging Face, and others. The project is being repositioned as a protocol layer for standardizing how RL environments are published and consumed by agents, rather than dictating reward frameworks or training logic. This move aims to enable open source models to achieve the same training efficiency that frontier labs achieve by co-optimizing models with their execution harnesses.
TL;DR
- OpenEnv governance shifts to a multi-stakeholder committee including Meta-PyTorch, Nvidia, Hugging Face, Modal, and others
- Project is being narrowed to focus on interoperability standards for RL environments using Gymnasium-style APIs and standard protocols like HTTP, WebSocket, and Docker
- OpenEnv will not dictate reward definitions or training loops, leaving those to specialized libraries while serving as a common interface layer
- Supported by 15+ organizations including PyTorch Foundation, vLLM, Lightning AI, and Scale AI
Why It Matters
Open source models currently lack the co-optimization between model and execution environment that proprietary systems like Claude Code and GPT-5.5 achieve. OpenEnv addresses this by providing a standardized protocol that allows any open source model to work efficiently with any execution harness, reducing the fragmentation that has prevented open source agents from matching frontier lab performance.
Business Impact
Organizations building or deploying agentic systems can now use a vendor-neutral standard for environment integration rather than building custom integrations for each model-harness combination. This reduces development overhead and enables faster iteration on agent training and specialization for specific tasks.
Key Implications
- Open source agent development gains infrastructure parity with frontier labs by enabling standardized model-harness co-optimization
- Developers can now train models on any compliant environment without writing bespoke code, lowering barriers to entry for agent training
- The protocol-first approach allows reward frameworks and training libraries to remain independent while interoperating through a common socket, preserving ecosystem diversity
What to Watch
Monitor adoption rates across open source projects and whether the committee structure remains effective as governance expands. Track whether this standardization actually enables open source models to match frontier lab efficiency gains in agent tasks, and whether competing standards emerge that fragment the ecosystem.
Subscribe to the newsletter
The latest stories and analysis, delivered to your inbox.
Free. No spam. Unsubscribe any time.



